Winning in Trump Country


Examining the Messaging Strategies of Two Democratic Newcomers Who Overcame the Red Tide in the 2022 Midterms
Given the 2022 midterms were marked by the defeats of many election deniers and January 6th apologists, a secondary focus of this study is to assess the difference in our candidates' messaging strategies against distinct types of opponents— one faced Joe Kent in WA, a 'Kooky' nominee who fully embraced the 2020 election conspiracies, and the other faced Jeremy Shaffer in PA, a mainstream Republican who acknowledged, though reluctantly, Joe Biden's 2020 victory. ### Methodology I applied unsupervised topic modeling techniques, beginning with Latent Dirichlet Allocation (LDA) as a baseline method and then using Non-Negative Matrix Factorization (NMF) on Twitter GloVe vectors for refined clustering. After generating the topic groupings, I searched through each candidate's Tweet corpus for words closely associated with these topics to compare how often each candidate messaged on these topics to assess differing strategies. I used cosine similarity calculations within the tweet vector space to determine which words were most semantically similar in each topic. ### Data Used 1. PVI score data was sourced from the [Cook Political Report](https://www.cookpolitical.com/cook-pvi/2023-partisan-voting-index/118-district-map-and-list). 2. 2022 Midterm Results were sourced from [The Daily Kos](https://www.dailykos.com/stories/2022/9/21/1742660/-The-ultimate-Daily-Kos-Elections-guide-to-all-of-our-data-sets). 3. The campaign tweets from Marie Gluesenkamp Pérez and Chris Deluzio were hand-copied from their twitter accounts [@MGPforCongress](https://twitter.com/mgpforcongress) and [@ChrisforPA](https://twitter.com/chrisforPA) 4. The 114th Congress tweets addended with characterization inputs was sourced from Crowdflower's Data For Everyone Library via [Kaggle](https://www.kaggle.com/datasets/crowdflower/political-social-media-posts/data). 5. GloVe models and vector arrays were sourced from [Jeffrey Pennington, Richard Socher, and Christopher D. Manning of Stanford](https://nlp.stanford.edu/projects/glove/) ### Selecting the Candidates **SYNOPSIS:** I determined which candidates to focus on through comparing their 2022 electoral margins with their district's Partisan Voter Index scores (PVI). I ultimately landed on Marie Gluesenkamp Pérez in WA-03, and Chris Deluzio in PA-17. Below documents the step-by-step process of determining the candidates of focus
Expand for Full Candidate Selection Process
To identify standout candidates, I devised a ‘Performance’ metric by calculating the difference between each district’s Partisan Voter Index (PVI) and the candidate’s electoral margin in 2022. PVI measures how partisan the district is compared to the nation as a whole, based on how the constituents of those districts voted in previous presidential elections. This approach identified those who significantly outperformed their district’s typical partisan lean.
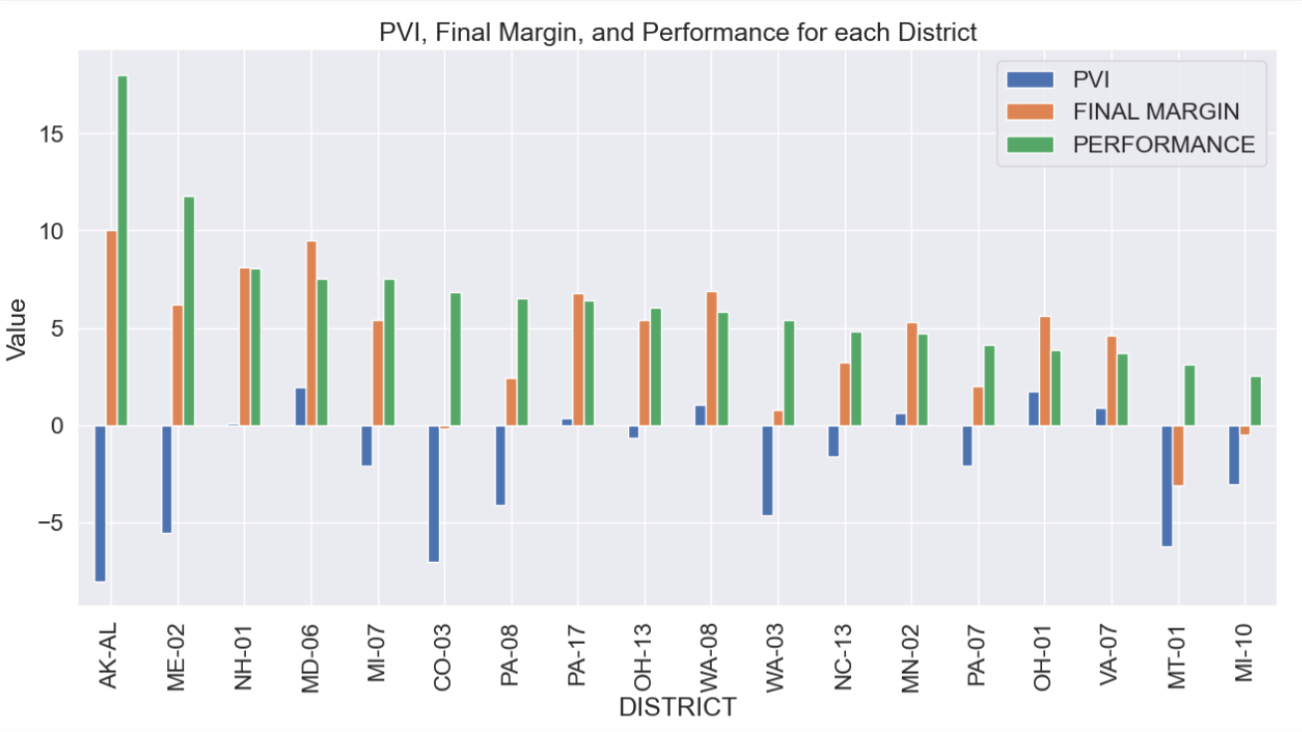
Of the top 18 overperforming candidates indicated in the graph above by district title, I narrowed my focus to first-time candidates to avoid any influence of incumbency effects. Mary Peltola from Alaska was also excluded due to the state’s use of Ranked Choice Voting, which, while I am personally a fan of RCV, complicates direct comparison of candidates in this context.
That left me with 6 candidates to consider, all having overperformed their districts’ partisan lean by at least 5 points. The following 4 candidates greatly overperformed in their districts, but were eliminated from consideration for various reasons:

Emilia Sykes would have been fun to analyze (and I love her glasses), but she deleted her campaign account following the election. Adam Frisch, who just barely fell short of victory in CO-03, was initially a candidate of interest, but was excluded due to the sheer volume of his tweets, which, thanks to Elon Musk’s recent termination of free API access for Twitter, made data collection too labor-intensive.
But ultimately, I found myself drawn to the candidate who arguably pulled off the biggest flip of the midterms. Her unique campaign and distinctive messaging strategy provided ample material for analysis, ultimately leading me to…

Marie Gluesenkamp Pérez! She faced cuckoo-bird Joe Kent, who expressed some extreme views like supporting the arrest of Dr. Anthony Fauci and endorsing the claims of a stolen 2020 election. In fact, he became the candidate for WA-03 after successfully primarying the serving Republican Congressperson, Jaime Herrera Beutler, one of only 10 republicans who voted to impeach Donald Trump following the events of January 6th.
The next candidate I wanted to assess took a little more research to come to a decision, but I wanted to find a Democrat who overperformed in their district, while contending against an opponent who was a more mainstream Republican. I landed on…

Chris Deluzio! He competed in a pure toss-up district and significantly outperformed against Jeremy Shaffer, who notably tried to sidestep affirming or denying the 2020 election fraud claims, and even released an ad promising to “protect women’s healthcare.”
Tweet Collection
As mentioned before, the termination of free API access meant manually compiling tweets for Chris Deluzio and Marie Gluesenkamp Pérez, and then using a custom parsing script to organize and format these tweets into a structured dataset for analysis. Tweets were manually copied, separated by a ‘|’ delimiter, and then organized into a corpus of around 1000 total tweets. candidate notebook.
Preprocessing Steps
Preprocessing Tweets:
Before feeding the tweets into the trained models, the corpus of each candidate was preprocessed:
- Tokenization: The tweets were broken into individual words or ‘tokens’, making it easier for our models to analyze the text.
- Word Averaging with Word2Vec:
- Word2Vec is a model that transforms words into vectors, capturing the semantic relationships between them. For example, Word2Vec understands that ‘king’ and ‘queen’ are related in a similar way as ‘man’ and ‘woman’.
- Word2Vec was used to convert the tokens into vectors, then averaged these vectors for each tweet. This process resulted in a numerical representation that captures the essence of each tweet, while making it digestible for machine learning models.
- Note on Lemmatization: Typically, natural language processing might include a lemmatization step, where words are reduced to their base or ‘lemma’ (e.g., “running” becomes “run”). However, Word2Vec has the ability to discern the semantic meaning of words in their various forms, so I opted not to lemmatize our tokens. This allows us to retain the variations in the language used in the tweets.
Normalization and Comparison:
Normalization was applied to the data for a balanced comparison of MGP’s and Deluzio’s messaging strategies:
Balancing Volumes– Due to the different numbers of tweets from each candidate, normalization allowed us to make comparisons based on tweet category proportions, not just total counts.
LDA uses these term frequencies to search for patterns and group things together into topics it thinks are related. It's up to the user to interpret these topics and discern underlying patterns. Sorting Marie Gluesenkamp Pérez's tweetset into 5 topics created the following key word associations to each topic for MGP:

It seems like Topic 1 involves canvassing and GOTV messaging with terms like "volunteer", "join", "doors", "Vancouver" (big population center in the district where running up turnout numbers would be important to win). The other topics' words offer some hints at overarching themes, but they are not as easy to discern as the first topic.
TF-IDF scores words based on frequency and rarity, then LDA identifies topics based on these scores. When determining topics, it assigns each word a weight indicating its importance to the topic. To demonstrate this concept, below is a bar graph showing the importance weights for the words in MGP's first topic. 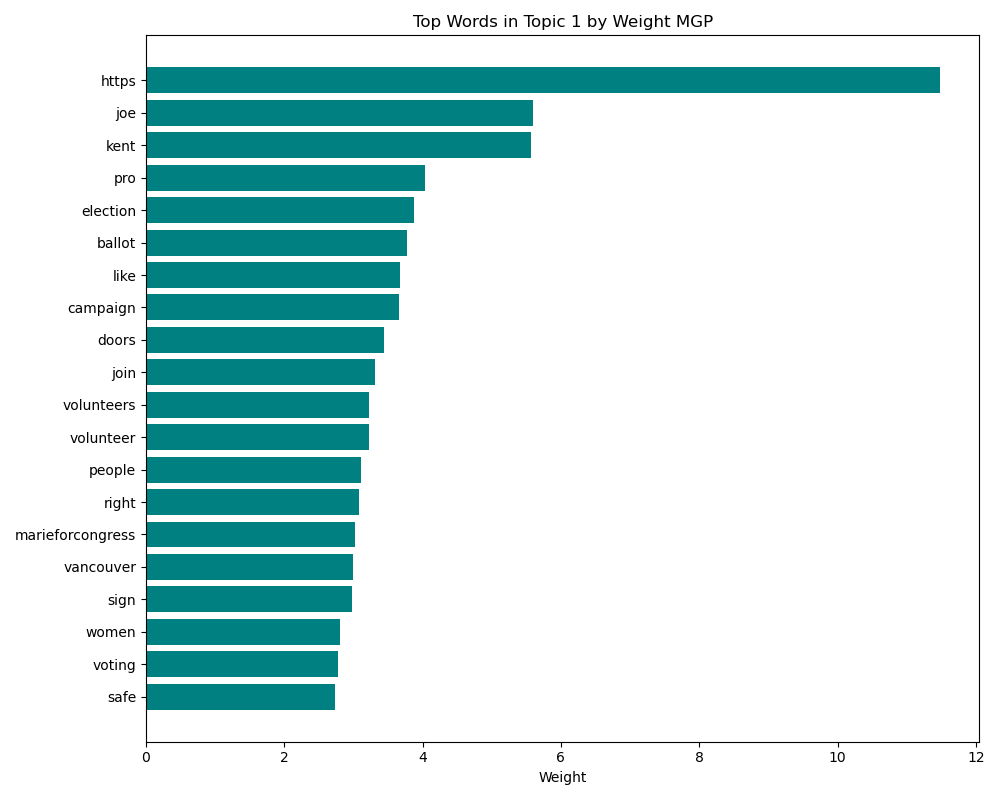 Now, this is all well and good, but it *is* a baseline model, so let's not dive too deep into it and see if we can go ahead and up the ante a bit with more complex modeling. ### Advanced Model -- Non-Negative Matrix Factorization (NMF) on 100-Dimensional Twitter GloVe Vectors #### GloVe (Global Vectors for Word Representation) GloVe is an unsupervised learning algorithm designed by [these dudes](https://nlp.stanford.edu/projects/glove/) at Stanford. It can train on any corpus, but the GloVe model I used was performed on 2 billion tweets, which is important for a few reasons. First, GloVe trains on word-word co-occurence rates, but my model is trained specifically on how words are used together and semantically similar **on Twitter.** Considering the normal corpora used for text classification, Twitter is not newspaper articles, or books, or technical journals, so the word-word codependence rates that develop on twitter are, to a large degree, affected by the character limit itself! Also, the language is more vernacular, and tweets are designed to be shared, commented on, and interacted with. It's just a different semantic universe from other corpora.
So, given all these aspects of twitter language, I used a model that vectorizes every word into 100-dimensional vectors. Word embeddings can better handle polysemy (words with multiple meanings) by providing contextually appropriate vectors, whereas TF-IDF used in my baseline model treats each word instance identically regardless of semantic context. #### Non-Negative Matrix Factorization Non-Negative Matrix Factorization (NMF) is a technique that decomposes high-dimensional datasets into lower-dimensional components. Compared to LDA on TF-IDF, NMF can handle denser data representations like GloVe embeddings more naturally, leveraging the semantic information embedded in word vectors. TF-IDF was like sorting through a giant word salad and counting the words that appear, but NMF with twitter-trained GloVe vectors knows that terms like 'Follow' and 'Mention' have related meaning in this semantic universe. This leads to better grouping and more interpretable and distinct topics. #### Process: After some limited pre-processing, each word within the tweets was converted into a 100-dimensional vector using the GloVe model. The word vectors were averaged to produce a single vector to represents each tweet. These tweet vectors were stacked into a matrix, which served as the input for the NMF model to break down into associated topics. Given the non-negativity constraint inherent in NMF, absolute values of the tweet vectors were utilized to ensure all inputs were non-negative. (I also tried shifting the vector values to all exist in positive space, but it didn't yield a noticeable improvement in the resulting topics.)
### Marie Gluesenkamp Pérez Topics Here is the distribution of unlabeled tweet topics that the model found to share semantic similarity (I found 7 topics to be the best grouping parameter). 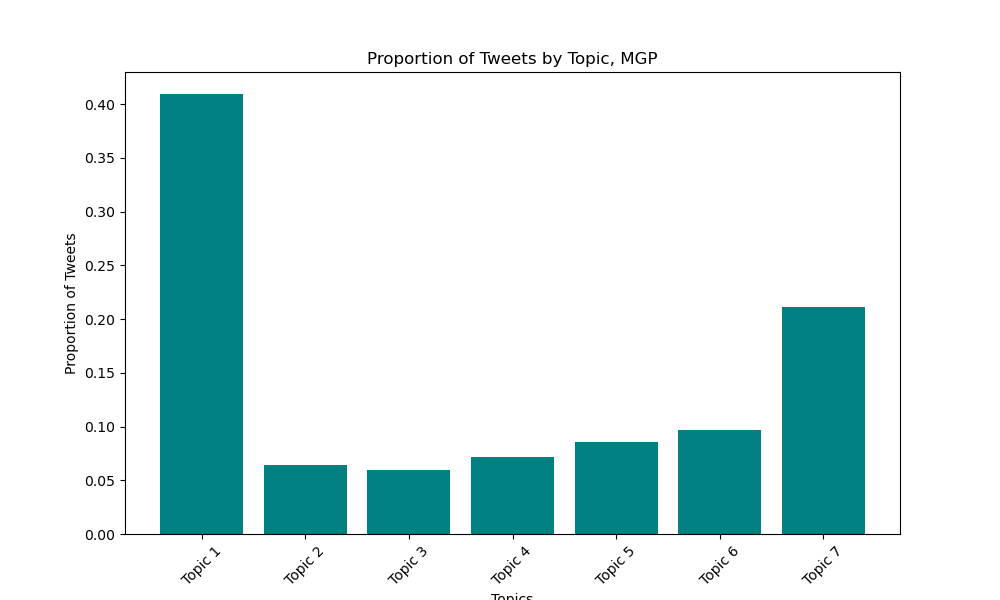 Once the tweets were grouped , I went through the top 50 tweets associated with each topic, and found the tweets to be best described by the following themes:
1. MGP Topic 1 – “Voice for Working Class”

2. MGP Topic 2 – “Digital & Community Engagement”

3. MGP Topic 3 – “Endorsements & Policy Priorities”

4. MGP Topic 4 – “Voter Mobilization Efforts”

5. MGP Topic 5 – “Anti-Extremism”

6. MGP Topic 6 – “Volunteer & Fundraising”

7. MGP Topic 7 – “Defending Rights & Freedoms”

1. Deluzio Topic 1 – “Union Solidarity & Local Empowerment”

2. Deluzio Topic 2 – “Reproductive Rights & Fighting Extremism”

3. Deluzio Topic 3 – “Community Events”

4. Deluzio Topic 4 – “Jobs & Infrastructure”

5. Deluzio Topic 5 – “Advocacy & Community Solidarity”

6. Deluzio Topic 6 – “Corporate Greed & Economic Fairness”

7. Deluzio Topic 7 – “Defending Rights & Democracy”

Vancouver canvass kick-offs! First we’ll rally, next I’ll say a few words, and then we’ll all go knock on doors to tell our neighbors about this
important race. RSVP and learn about other upcoming events here:
https://mobilize.us/marieforcongress/', >'Hello from Pacific County, where we’re having fun in the rain at the South Bend Labor Day parade! Our campaign is powered by volunteers like you. Join us at our next event ➡️
http://marieforcongress.com/volunteer/', **Summary:** Both campaigns effectively leveraged the national issues of 2022, such as abortion rights and anti-extremism, in their strategies. Deluzio capitalized on his district-specific issues, particularly unions, to resonate with his electorate. In contrast, MGP used more of her messaging capital on structuring her ground game, using her voice and reach to mobilize volunteers and supporters to turn out the right votes in the right places.